|
ESTONIAN SOCIAL SCIENCE ONLINE |
|
Andmed on informatsiooni üleskirjutus (mingis keeles) eesmärgiga informatsiooni säilitada ja edastada. Informatsiooni kvaliteet sõltub teisendusest informatsioon → andmed, andmete struktureerimisest ja säilitamisest andmebaasides, millest omakorda sõltub päringu võimalikkus ja kvaliteet ning lõpuks teisendusest andmed → informatsioon. Ahel on nii tugev, kui tugev on ahela nõrgim lüli… Kuna sotsiaalteaduste andmebaasides sisalduv informatsioon on saadud vastustena küsimustele on ahel veelgi pikem… See ahel algab küsimustike (ankeetide) koostajate teadmistest oskustest kogemustest mida nad kasutavad ankeetide koostamisel nii selles osas mida nad tahavad küsida, kuidas nad seda teevad, kui ka mida nad tahavad (mida on võimalik) vastustega hiljem ette võtta. Jätkub vastajate valikuga, väljavalitute valduses oleva oskuse ja kompetentsuse kasutamisega küsimustest arusaamiseks ja vastuste esitamiseks. Enamasti jätkub see ahel saadud vastuste kodeerimise ja andmete sisestamisega, et neist moodustuks lõpuks andmefail, mida on võimalik kasutada andmeanalüüsis andmestikuna. Seega on informatsiooni kvaliteet globaliseeruvate sotsiaalteaduste andmebaasides vaadeldav ühe keerulise protsessi tulemi kvaliteedina. Selle tulemi kvaliteeti saab parandada protsessi komponentide tulemite kvaliteeti parandades ja parendades protsessi ennast. Suured vead protsessi alguses on halvim, mis juhtuda saab, sest see muudab tihti kogu järgneva töö kasutuks. Mida on siis võimalik teha? Vaatame kõigepealt kuidas aidata küsimuste koostajaid. Pakun siin välja mõned võimalused, mis eraldi võetuna on arvatavasti juba paljudes andmeanalüüsiga tegelevates keskustes kasutusel[1]
Valdkonna infoloogiline modelleerimine on keeruline töö ja pole üheselt teostatav. Seepärast võiks luua ja arendada paralleelselt ka mitut mudelit. Oluline on, et küsimustike koostajatel oleks hea ettekujutus, milliste infoobjektide atribuutide väärtusi neil konkreetse probleemi lahendamisel küsida tuleb. Samuti on võimalik vaadata ja kasutada juba varem kasutatud küsimusi ning hinnanguid ja kommentaare nende sobivusele ühel või teisel juhul.
Säilitades ja süstematiseerides ankeetide küsimustikke, modelleerides infoloogiliselt keskkonda ja uurimisobjekti ning sidudes küsimusi saadud mudeliga, lisades neile informatsiooni küsimuste kaudu kogutud andmete vastavusest tegelikkusele ja nende informatiivsusest, loome hea baasi kvaliteetseks andmekogumiseks.
Küsimustike koostamisele järgnevad küsitluste läbiviimine, andmete kodeerimine (tavaliselt tehakse see juba suuremas osas küsimuste koostamise ajal ja vajadusel vaid täiendatakse) ja sisestamine arvutisse (andmefaili koostamine). Info- ja kommunikatsioonitehnoloogia kiire arengu tulemusena on oodata nende protsesside kokkusulamist üheks tervikuks, mis vähendab töö kulu ja vigade tekke võimalusi. Kuni toimub veel andmete käsitsisisestus on mõistlik luua ja kasutada sisestusprogramme, mis automaatselt kontrollivad sisestatavat materjali vastavust eeldatavale väärtusvarule ja andmete loogilist terviklikkust. Lisades eelpool kirjeldatud mudelisse küsimusele ka vastuse väärtusvaru, on võimalik sisestusprogramme automaatselt genereerida.
Andmestike ollakse harjutud hoidma failides. Tavaliselt on andmestik sisestatud mingi “andmeanalüüsi oskava” rakenduspaketi abil. Sotsiaalteadustes on selleks viimasel ajal valdavalt SPSS. See pakett ja ka teised paketid vajutavad andmetele ja nende kirjeldamisele oma pitseri. Andmeid hoitakse ühetabelilises nn lameandmebaasis normaliseerimata kujul ja tunnuste kirjeldamiseks on vaid mõned standard atribuudid nagu nimi, andmetüüp, puuduva väärtuse koodid jne. Lisaks on võimalik veel kodeeritud väärtustele nimesid anda, kuid sellega tavaliselt võimalused ammenduvad. Tihtipeale on salvestatud vaid kodeeritud vastused. Teades küsimusi, omades andmeid küsimuste eesmärkidest, kontekstist, esitamise viisist, ajast, esitajast ja vastajast on meie käsutuses märgatavalt rohkem informatsiooni, mis võimaldab teostada kvaliteetsemat analüüsi. Samuti aitab tulemuste interpreteerimisele kaasa üleüldise sotsiaalpoliitilise ja majanduspoliitilise tausta tundmine. Hea oleks olla teadlik sündmustest, mis võisid vastuseid mõjutada. See teadmine võiks meta-andmetena olla salvestatud andmestiku juurde. Uuringut läbi viies on kogenud uurijal palju lisainformatsiooni, kuid tavaliselt jääb see andmestikuga seostamata. Sageli juhtub ka seda, et kogutud andmete analüüs jääb pinnapealseks või huvitab uurijat vaid mingi kitsam probleem, mille tõttu uuritakse andmeid vaid kindlast vaatepunktist lähtuvalt. Viimasel ajal on hakatud andmestikke organiseerima andmebaasidesse, lisades mõningat teavet andmestike saamisloo kohta ja pakkudes ülevaadet saadud uurimistulemustest (viited avaldatud artiklitest). Näiteks: The European Social Survey http://ess.nsd.uib.no, Eesti Sotsiaalteaduslik Andmearhiiv http://www.psych.ut.ee/esta/ jt. See tutvustab tehtut, annab võimaluse korduv uuringuteks ja täiendavateks uuringuteks sama andmestiku piires.
Andmebaasi kõige väärtuslikum osa on kahtlemata andmed - vastused küsimustele. Omades meta-andmeid on vastused palju informatiivsemad. Peale andmestiku sisestamist ja esialgset töötlust võiks andmestiku kuuluvad andmed säilitamiseks ringi organiseerida ja lisada koos esialgsete meta-andmetega vastavalt valdkonna infoloogilisele mudelile struktureeritud andmelattu (Data Store). Ehk teiste sõnadega andmed normaliseeritakse vastavalt valdkonna mudelile ja lisatakse ühtsesse andmelattu säilitades sidemed esialgse andmebaasiga. Seeläbi täieneksid iga uurimusega nii uuringute andmebaas, kui ka valdkonna andmeladu. Meta-andmeid võiks täiendada ka analüüsi käigus ja moodustada sellega nn andmestiku passi, mis aitaks tulevikus hinnata andmete sobivust ühe või teise uurimuse tarbeks. Sellise andmelao kasutuselevõtt looks võimalusi uutele uuringutele vaadeldava valdkonna raames.
Uurimus saab alguse mõnest huvitavast probleemist (juhuslik) või kuna töötatakse koos inimestega, kes on uurinud mingit probleemi juba aastaid, liitutakse selle probleemi uurimisega (determineeritud). Võibolla on võimalik seda tegevust korrastada – analüüsida ja modelleerida uurimisvaldkondi, leida valdkondade vahelisi seosed, siduda mudelid andmetega ja luua nii uue kvaliteedi tekkevõimalus uurimustes. Uurimisvaldkonna mudel peaks sisaldama kindlasti andmevaadet ja võibolla ka protsessivaadet või käitumisvaadet. Andmevaade kirjeldatakse tavaliselt olemi-suhte diagrammiga (Entity Relationship Diagram) (ERD). See diagramm sisaldab infoobjektide (olemite) kirjeldusi atribuutide kaudu ja olemitevahelisi seoseid. Protsessivaade võiks olla esitatud andmevoo diagrammi (Data Flow Diagram) (DFD) kaudu, mis seob valdkonnas toimuvaid protsesse ja nende vahel liikuvaid andmeid. Alternatiivina võib kasutada ka käitumisdiagrammi (Task Communication Diagram) (TCD), mis seob protsesse, andmeid ja tegijaid (ressursse). Lisaks valdkonda illustreerivale funktsioonile on andmevaatel veel teinegi funktsioon. See sobib andmelao kirjelduse alusmaterjaliks määrates selle esialgse struktuuri, mida tuleb täiendada meta-andmete (uurimuste kirjelduste ja nendes kasutatud valimite valimiseeskirjade ja kirjelduste) tarvis. Et mitte jääda vaid arutluste tasemele vaatame, kuidas see protsess võiks toimuda. Näiteks valisin ühe fragmendi uuringust The European Social Survey, täpsemalt SELF-COMPLETION QUESTIONNAIRE S-C-C (Round 2 2004), milles on 3 küsimust vastaja otseseks määratlemiseks, 21 küsimust isiku omaduste hindamiseks (mõlema soo jaoks eraldi), 3 küsimust seoses arsti juures käimisega, 3 küsimust seoses vastaja tööga (vastatakse, juhul kui vastaja töötab), 3 küsimust vastaja rahulolu hindamiseks riigis toimuvaga ja 3 küsimust hindamaks kuivõrd vastaja riiki usaldab. Vastavad tunnused on kujutatud info-objektina joonisel 1.

Joonis 1. Ankeedi vastustega väärtustatud tunnused
Infoobjekt realiseerub relatsioonilises andmebaasis tabelina, mis varustatakse primaarvõtmega (PK), kui selles tabelis sisalduvaid andmeid kasutatakse koos teis(t)e tabeli(te) andmetega ja võõrvõtmega (FK), kui tabel sisaldab andmeid teisest tabelist. Joonisel 1 esitatud andmetabel on normaliseerimata või madalaimal normaliseeritud kujul (I normaal-kujul). Jagame tabeli osadeks tuues sealt välja isiku omadusi hindavad andmed. Lisame tabelid uuringute kirjeldamiseks ja hinnangute skaalade kirjeldamiseks ning küsitlusaja salvestamiseks. Tabel Uurimus&Isik seob tabeleid Person ja Uuring võõrvõtmete kaudu, ehk selles tabelis on kirjas millis(t)es uuringu(te)s isik osales ja ka vastupidi – kes osalesid uuringus.
Tabel Isik&Omadus sisaldab hinnangut isikuomadusele ja näitab, millise isikuomaduse (tabel Omadus) ja millise isikuga (tabel Person) see seotud on. Samuti on tabelis kirjas viide ajale (tabel Küsitluseaeg) ja hinnangu skaalale (tabel Skaala) vt joonis 2.
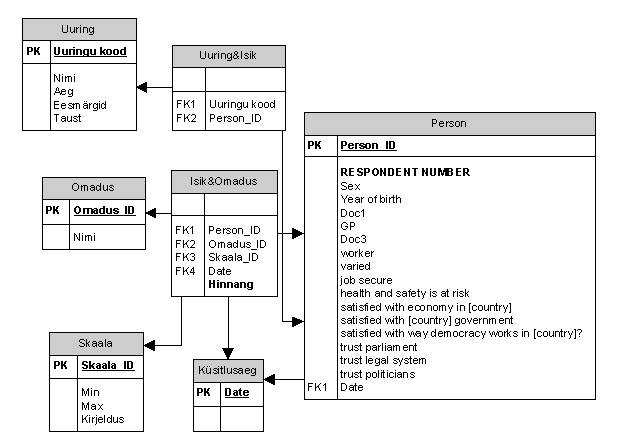
Joonis 2. Isiku omaduste hinnangud on esitatud normaliseeritud kujul, ning lisatud informatsioon uuringu kohta
Erinevates uuringutes võib olla ühe ja sama parameetri “mõõtmiseks” esitatud küsimus sõnastatud erinevalt. Seega tuleb koos vastusega salvestada ka küsimus.
Ka normaliseerimisprotsessi võib jätkata. Näiteks toome tabelist Person välja eraldi tabeliks arstijuures käimist puudutavate küsimuste vastustest moodustunud tunnused vt joonis 3.
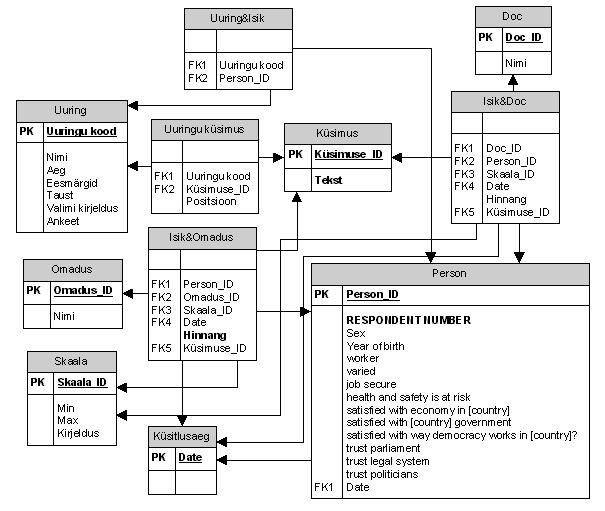
Joonis 3. Andmemudelisse on lisandunud tabel Küsimus ja on jätkunud normaliseerimisprotsess isiku suhtumist arstijuures käimisesse iseloomustavate andmete osas
Normaliseerimist jätkates näeme, et tekivad omavahel sarnased tabelid: Isik&Omadus, Isik&Doc,…, Isik&Usaldus. Seda arvesse võttes võime teha veel ühe üldistava sammu ja modelleerida kõiki tunnuseid ühises tabelis lisades tabelisse tunnuse grupi vt joonis 4.
Kuidas ja kui kaugele modelleerimisega igal konkreetsel juhul minna jäägu mudelite koostajate otsustada…
Mida selline andmetenormaliseerimine ja varustamine “meta-andmetega” annab:
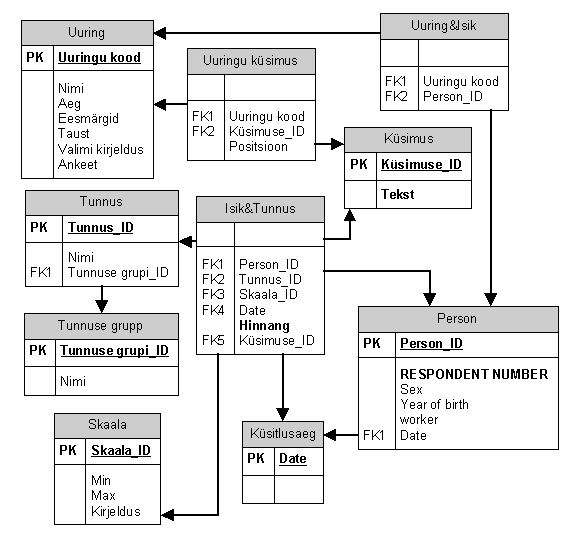
Joonis 4. Kõiki tunnuseid modelleeritakse ühises tabelis kasutades grupeerivat tabelivälja e atribuuti
Andmebaaside integreerimisvõimalusi on mitmeid. Sidudes andmestikud mudelitega võime saada integratsiooni tunnuste, tunnuste gruppide, indiviidide, indiviidi gruppide ja andmestike tasanditel. Andmebaaside seostamine mudeliga annab paremad võimalused uurimuste kavandamiseks ja seni kogutud andmete kasutamiseks. Andmestike täiendav kirjeldamine ja kirjelduste liitmine mudelite ja andmebaasidega ning andmeladude moodustamine aitab suurendada uurimuste mahtu ja parandada kvaliteeti. Andmemahtude suurenemine teeb võimalikuks ka mittestatistiliste meetodite kasutamise nn andmekaevandamise (Data Mining) kasutuselevõtu – teadmiste avastamise (Knowledge Discovery) arvutite abil. Selline tegutsemine pole aga võimalik ilma korralikult funktsioneerivate infosüsteemide ja hästi struktureeritud andmeladudeta. Kõik see omakorda vajab tugevat organisatsioonilist toetust.
Kokkuvõtteks
Selleks, et kogutud andmeid paremini uurida, saada kätte nendesse salvestatud informatsioon - parandada uurimuste kvaliteeti, tuleks andmeid hoida andmebaasides – andmeladudes, koos mete-andmetega: andme-, tausta- ja kogumiskirjeldusega. Uurimuseks vajalike andmete kogumine õnnestuks paremini ja oleks lihtsamini teostatav, kui uurimisvaldkond oleks eelnevalt infoloogiliselt modelleeritud ja selle valdkonna uurimiseks varem kasutatud küsimused ja kogutud vastused oleksid seotud uurimisvaldkonna infoloogilise mudeliga. Selline lähenemine võimaldab integreerida erinevate uuringute käigus kogutud andmed ja formeerida neist andmestikke uute uuringute läbiviimiseks. Samuti annab see võimaluse andmekaevandamise ja teadmiste avastamiseks meetodite kasutamiseks valdkonna integreeritud andmebaasides.
Summary
High quality in data analyses needs high quality data. Such data quality is related with quality of questionnaire, fieldwork and databases. To enlarge the quality of data analyses, we need to know more about data: what were the goals of questioners; how was made the questionnaire; what was background of questionnaire; how was fieldwork planned and made ; what were the events to influence on answers; how are the data described, structured and saved in databases and so on… We need meta-data. People who makes questionnaire must know the investigation area very well. One way to solve this problem is to model this area – model its data and dataflow. This model is also basis for Data Store structure holding data, meta-data and questionnaire of any investigation in this area. It gives the opportunity to integrate data and use data mining and knowledge discovery in investments.
Creating ER Diagrams with Visio Pro
http://www.utexas.edu/courses/mis325/tutorial/visio/visio.htm sept. 2004
Data Warehousing.
http://www.sas.com/technologies/dw/index.html?sgc=g sept. 2004
Developing Entity Relationship Diagrams (ERDs)
http://infocom.cqu.edu.au/Courses/spr2000/95169/Extra_Examples/ERD.htm sept. 2004
European Social Survey,
http://www.europeansocialsurvey.org/ sept.2004
Graham Wideman, Visio 2002 Developer's Survival Pack (Trafford Publishing 2003):
HOW TO DRAW DATA FLOW DIAGRAMS http://www.smartdraw.com/tutorials/software-dfd/dfd.htm sept. 2004
How to Draw Entity Relationship Diagrams (ERD)
http://fmpdev.com/files/ERD.pdf sept. 2004
Leping, V., Oja, U. ON A TOOL OF OPTIMISATION THE SOCIAL RESEARCH PROCEDURES AND ITS APPLICATIONS IN TEACHING 5th International Conference on information systems, analysis and synthesis: ISAS'99
Michael Berry & Gordon Linoff, Mastering Data Mining, John Wiley & Sons, 2000.
Paolo Giudici, Applied Data Mining: Statistical Methods for Business and Industry, John Wiley, 376pp, 2003.
[1] Ei oska küll ühtegi nimetada, aga mõte on nii lihtne ja loomulik, et kindlasti on see juba paljudel pähe tulnud.